



At my current client we experienced a nasty surprise when enabling balance-tcp (802.3ad) on our Nutanix cluster. We always follow the same procedure as below:
- Configure LACP on the Arista switches first
- Configure the LACP setting on the Arista switches before making changes on the Nutanix cluster
- The Nutanix cluster is in an Active-Passive configuration so the active link will maintain connectivity while you configure the switches
- Use the appropriate LACP mode (typically active mode on both ends) and ensure the LAG (Link Aggregation Group) is correctly configured with the same LACP key and parameters
- Validate Switch Configuration
- Confirm that LACP is active and ready on the switch ports (e.g using
show lacp interfaceson Arista) - Ensure that the ports are correctly bundled into a LAG without errors
- Confirm that LACP is active and ready on the switch ports (e.g using
- Switch the Nutanix cluster to Active-Active (LACP or Balance-TCP)
- Once the switch side is ready, update the Nutanix cluster NIC bonding to Active-Active mode via Prism
- Ensure that the bond policy matches the LACP settings from the switches
- Verify connectivity
- Confirm that LACP negotiation is successful and that both NICs are active by checking the bond status
- Verify that the cluster is reachable and there is no packet loss
- Test and Monitor
- Perform a failover test by disabling one of the LACP member links to ensure redundancy is functioning correctly
- Monitor for any issues using Arista and Nutanix logs
Seems pretty straightforward and we never had any issues with following this process until it did. After enabling LACP on our switches the Nutanix cluster (still on active-backup) was unreachable, so we reverted the change a.s.a.p. and checked what is happening here.
PS: We’re doing this on 3 different locations and on the first location we didn’t experience any issues.
We checked this document where we noticed a new (to us) setting for LACP fallback on the Arista switches:
lacp fallback individual
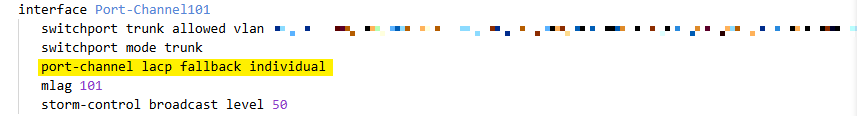
So back to the Arista switches and setting this parameter on one of our port channels and checking if we could reach the node connected on that port. Hurray we got contact, so we know what to do.
As the cluster we need to update is already hosting workloads we wanted to ensure we don’t loose any connectivity (some big Oracle Databases are running) during the enablement of LACP on the switches so we came up with the following.
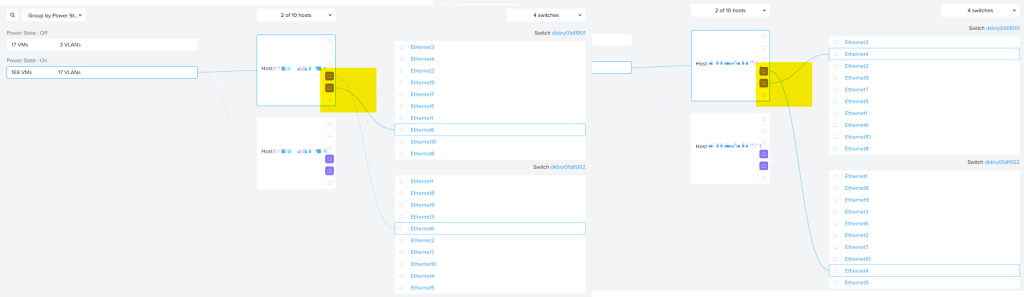
- First thing is validating which node is connected to which ports on which switch (e.g Node 1 to eth1 on Switch1 & 2)
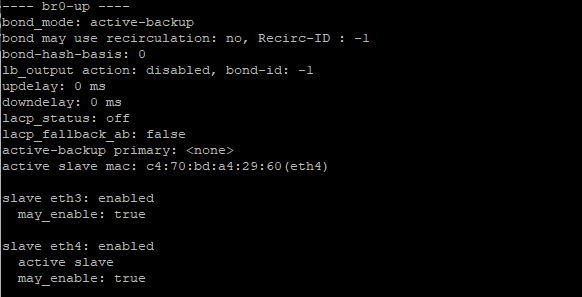
- Check which nic is currently active on the node via
ovs-appctl bond/show(it’s the active slave one) - Update the switch port for the backup link (so the inactive one)
- Forcibly change the active NIC in the bond via
ovs-vsctl set port bro-up other_config:bond-primary=ethX - Update the switch port for this node on the second switch.
- Repeat until you updated all ports and nodes.
After this is done we can start the change in bond-mode to active-active. To do this we use the Prism Virtual Switch UI as this will configure all AHV hosts with the fast setting for LACP speed and sets LACP fallback to active-backup on all AHV hosts. As the AHV hosts need a reboot to enable this setting doing this via the GUI means the rolling reboot is also being dealt with so it’s a matter of ease.
Top-tip…
If you don’t need to change your bond-mode but want to reboot your switches and ensure zero downtime you can change the active NIC via the ovs-vsctl command to ensure your active connections are flowing via the other switch. After the reboot repeat the same (just ensure you pick the other NICs) and you can safely reboot your switches.
Afterwards remove the primary NIC reference via ovs-vsctl remove port br0-up other:config:bond-primary=ethX